2 日前、GitHub と OpenAI が、人工知能を使用してコードを自動補完および生成できるツールである GitHub Copilot を開始したと発表しました。
GitHub Copilot が人間によって書かれた既存のコードから「学習」し、コードの断片 (場合によっては完全な機能) を提案できることは、機械学習の進歩を示す素晴らしいニュースです…しかし、それは他の分野で疑問と不安を引き起こします。
その 1 つは労働力です(AI がプログラミングを学習している今、開発者に未来はあるのでしょうか?)。もう 1 つは、結果として得られるソフトウェアがどのライセンスの対象となるかを決定する際に困難を伴うため、厳密に合法です。
“として?” ―「Copilot の支援があれば、自分がプログラムするソフトウェアのライセンスを決めることはできないのですか?」と疑問に思うかもしれません。
そうですね、その質問に対する答えに関しては全会一致はありません。プログラマー@eeveeの次のようなツイートを受けて、 HackerNews上で活発な議論が始まりました。
「GitHub Pilot は、自ら認めているように、山ほどの GPL コードで訓練を受けてきたため、これが商用プロジェクトで [使用できる] ようにオープンソースをホワイトウォッシュする方法ではないことが私にはわかりません。」というあなたの声明通常、正確なフラグメントは再現されませんが、あまり満足のいくものではありません。
「著作権には『コピーペースト』だけでなく、二次的著作物も含まれます」と彼はスレッドで説明を続けている。そして、GitHub Copilot が「知っている」ものはすべてオープン ソース コードから抽出されたものであるため、「これを含まない「派生 [作品]」の解釈は不可能です。」
@eevee 氏によると、前世代のニューラル ネットワークでは、著作権を主張するのが難しかったテキストと写真に焦点を当てていたため、法的問題が軽減されました。
「しかし、これはすでに法廷で検証された、明確にライセンスされた作品に基づいているので、避けられない集団訴訟を楽しみにしています。」
私のコードを使用したくない場合はどうすればよいですか?
これまで見てきたことを考慮すると、あなたが GitHub リポジトリで新しいオープン ソース プロジェクトの開発を始めようとしている開発者で、自分のコードを GitHub CoPilot に「フィード」するために使用されたくない場合はどうすればよいでしょうか? 「このコードはコード生成モデルのトレーニングには使用できません」という通知を含むカスタム ライセンスを使用するだけで十分でしょうか?
私たちはそう考えるかもしれません。そうしないと、GitHub は明らかなライセンス違反を被ることになります。ただし、 GitHub の利用規約によれば、コンテンツをアップロードするたびに、「サービスの改善」を目的としてそのコンテンツを使用する許可をプラットフォームに付与します。これは、ライセンスに指定されている範囲を超えて明示的に許可を与えることを意味します。
確かに、GitHub の利用規約では、私たちがコードを第三者に販売する権利を彼らに与えていないことを明確にしていますが、それをデータベースや検索インデックスに含めたり、共有したり見せたりする権利は与えています。他のユーザーも。
したがって、GitHub CoPilot の助けを借りてプログラムされたソフトウェアのライセンスに関して最終的に訴訟が起こった場合、最終的な責任は、アシスタントの提案を受け入れたユーザーにあることになります。
GitHub には解決策があります。開発者に通知し、開発者に決定してもらいます。
GitHub Copilot のドキュメントは、潜在的な法的論争については明示的には扱っていませんが、 コード提案の性質を分析しようとしており、プラットフォームが「オウム」 (「確率的オウム」の技術概念を指します) なのか、それとも「オウム」なのかを修辞的に問いかけています。カラス」。
「多くの場合、それは(聞いたことを繰り返す)オウムではなく、小さなブロックから新しい道具を組み立てるカラスのように見えます。」
この文書には、 Copilot が「トレーニング中に見たコードを繰り返す」頻度を調べるために、同社の約 300 人の従業員を対象に実験が行われたと記載されています。 Python を使用して、合計 453,307 個の繰り返し提案を生成します。
「たくさんありますが、その多くは単なる句読点と正規表現であったため、すぐに無視できます。」
結果の連続的なフィルタリングには、(自然数、素数、さまざまなアルファベットの文字、または株式市場ティッカーの) リストなどの標準コード フラグメントが含まれていました。
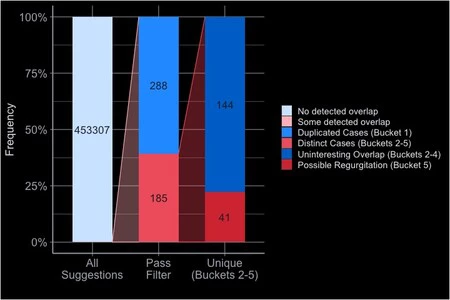
最終的に、関連するコードの断片が効果的に繰り返されるコードの「逆流」のケースを合計 41 件検出することになりました。
「これは、10 週間のユーザーあたり 1 件の吐き戻しイベントに相当します。[…] それほど多くないようですが、確かに 0 件に相当するわけではありません。」
このため、彼らは最終的にツールに統合する予定のソリューションを提供しています(現時点では、プレビュー バージョンとしてのみ利用可能であることを覚えておいてください):重複検出機能。これは、提案されたコードが正しいかどうかをユーザーに通知します。関連する重複。 「その後、ユーザーは適切な帰属を含めるか、いかなる形でもコードを使用しないことを決定することができます。」