📖
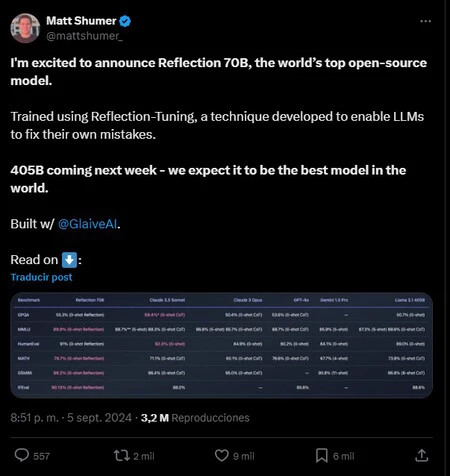
9月5日、HyperWrite AIの共同創設者兼CEOであるマット・シューマー氏は、 「Reflection 70B」と呼ばれる新しいAIモデルの発売をTwitterで発表した。 Matt の説明によると、このモデルは Meta が開発した人気モデル Llama 70B を微調整したバージョンだそうです。
「微調整」とは何ですか?これは、特定のタスクで事前トレーニングされたモデルを微調整して、別の同様のタスクまたはより特殊なタスクに適応させるプロセスです。最初から再トレーニングするのではなく (時間とリソースの点で非常にコストがかかります)、微調整します。問題のタスクに固有のより小さなデータセットを使用します。
マット氏によれば、Reflection 70B が Llama と異なる点は、次のような複雑なプロンプト手法を通じて推論する能力が強化されたことです。
- 思考連鎖:結論や答えに到達する前に、モデルに段階的な推論を実行させる手法。このモデルは、即座に答えを提供するのではなく、問題をいくつかの段階に分割し、特に数学的、論理的、または複数のステップからなる問題において、より多くの情報を考慮して、より正確で一貫した答えを生成できるようにします。
- リフレクション:リフレクション手法には、最終的な答えを与える前に、モデルが自身の反応や思考プロセスをレビューすることが含まれます。これは、モデルが初期応答の品質を反映する自己分析のようなもので、精度が向上し、エラーが最小限に抑えられます。
Matt 氏によると、これらの技術を使用するだけで、このモデルは Llama 70B の限界を克服し、 Llama 405B と同様の性能を達成することができました。
もちろん、この発表は UA コミュニティに波紋を呼びました。結局のところ、Llama モデルの単なる調整でこのような高度なレベルの推論が提供できるのであれば、これは、能力の低いAI モデルを改善するための重要なステップとなる可能性があります。パラメータ。
最初のテスト: 明らかな成功
発表後、Matt はモデルの API へのアクセスを提供し、他のユーザーが Reflection 70B をテストできるようにしました。最初の数時間で、API にアクセスできた人々は、非常に有望な結果を報告しました。モデルの反応は、少なくとも最初は、マットが約束したことを裏付けるものであるように見えました。
1 つの特定のケースが際立っていました。モデルは、多くの AI がよく間違える質問に正しく答えたため、早期採用者は、このモデルが実際に大きな進歩を示していると信じるようになりました。
ちなみに問題は、 「0から100までの数字のリストで、アルファベット順でどれが最初ですか?」というものでした。 。ほとんどの AI モデルはこのタスクを間違える傾向があり、「ゼロ」または別の間違った数値のような答えを返します。しかし、Reflection 70B は、アルファベット順の最初の数字が「14」であると正解しました。
新しいモデルをめぐる誇大宣伝は急速に高まり、AI コミュニティの数人の影響力者 (普及者と専門家の両方)が Reflection 70B に対する肯定的な印象を共有し始めました。しかし、この楽観主義は長くは続かないでしょう。
砂上の楼閣の崩壊
その後間もなく、事態は悪化し始めました。(Shamer が提供する API からアクセスするのではなく) Hugging Face パブリック リポジトリからモデルをダウンロードできた人々は、Reflection 70B のパフォーマンスが発表されたものと異なることにすぐに気づき始めました。そして、サードパーティのテストではマットが共有した最初の結果は再現されませんでした。
Matt がモデルの間違った部分をリポジトリにアップロードし、異なるバージョンの Llama を混在させたと主張したため、状況はさらに混乱しました。
この説明は当初一部の人に受け入れられましたが、問題や矛盾を報告するユーザーが増え、モデルが期待どおりに機能しないことが続くと、 Reflection 70B の信頼性について疑問が生じ始めました。
暴露と詐欺
モデルを操作してその起源を特定するよう求めると、ユーザーは Llama の微調整ではなく、別の AI を扱っていることを示す応答を受け取りました。最終的に、 Matt によって提供された API アクセスが Reflection 70B ではなく、完全に異なる AI モデルであるAnthropic の Claude 3.5に接続されていることが判明しました。
この発見はコミュニティに怒りの波を引き起こしました。多くの人が技術的な進歩だと信じていたものは、純粋な煙であることが判明しました。マット・シェイマー氏はAIの分野で尊敬される人物とみなされていたが、彼に対する詐欺疑惑が急増している。この暴露を受けて彼はまだ公には発言していないが、この事件は彼のキャリアに大きな影響を与える可能性が高い。