近年、多くの分野で人工知能に基づく素晴らしいツールが登場しています。 Microsoft のような企業も、この点に関して無限の提案を行っており、その最新のものの 1 つが VALL-E です。
VALL-E ( DALL-Eと混同しないでください) は、対話者と同じ声とイントネーションの音声を生成できる言語モデルです。ツールが処理を開始できるようにするために必要なのは、少なくとも 3 秒の音声だけです。
人のイントネーションや感情まで真似できるAI
この言語モデルの機能については、研究者が発行したレポートで詳しく説明されています。 VALL-E は、60,000 時間以上の英語音声でトレーニングを受けています。このテクノロジーにより、ユーザーは別の人の声からパーソナライズされた音声を合成できます。実際、研究では、実施されたテストの成功が反映されています。
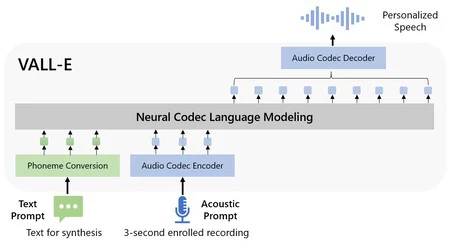
「実験結果は、音声の自然さと話者の類似性の点で、VALL-E が最先端のゼロショット TTS システムよりも大幅に優れていることを示しています。」さらに、VALL-E が話者の感情と音響環境を保存できることもわかりました。合成における音響メッセージの。」
GitHubページには、このツールがどのように機能するかを示す例が多数あります。ここでは、数秒の音声で、システムがまったく異なるメッセージの音声とイントネーションを確立できることがわかります。印象的ではありますが、その結果には依然としてオーディオに「ロボットの」抜け穴があり、このタイプの提案ではよくあることです。
しかし、おそらく最も驚くべきことは、メッセージに含まれる感情を模倣するツールの機能です。つまり、誰かが怒りや悲しみを示した場合、AIはそのイントネーションを拾い上げて、まったく異なるメッセージに適用することができるということです。
このツールのパフォーマンスは非常に優れていますが、Microsoft は変化が知覚できなくなるまで改良を続ける可能性があります。もちろん、テクノロジーは大きな利点をもたらしますが、特に誰かになりすます場合には、非常に危険な場合もあります。