📖
「以下の文章は、公開許可を与えた公開Discordサーバー上の匿名の人物によって共有された漏洩文書です。これはGoogleの研究者からのものです。この文書はGoogle従業員の意見にすぎません。会社全体ではありません。当社はその真正性を確認しています。
これは、コンサルティング会社セミアナリシスのニュースレターに昨年掲載された記事の見出しの文章だ。当時、技術分野からはその信頼性を支持する声がいくつかありました。そのため、Django の共同作成者 (レポートで引用されている) である Simon Willison は、これを「私がこれまでに見た LLM に関する文章の中で最も興味深い」と述べました。長い間。「時間」であり、信頼性スケールで「8」を与えました。
「これを読んでみると、これは Google 内で流通していると予想される類の文書であり、なぜこれほど優れたものを書いたのに、それを自分の手柄とせずにリークのふりをする人がいるのか、私には理解できません。」
問題の報告書は、基本的な考え方を中心に展開している。つまり、OpenAI と Google は互いに競争し続けている (または Google が OpenAI と競争しようとしているが、それは見方によって異なる) 一方で、彼らの進歩は現在行われている取り組みによって少しずつ覆い隠されているというものだ。 「オープンソース」コミュニティの実施が完了しました。
その著者は、Google と OpenAI のモデルが品質の点で依然として若干の優位性を保っているものの、 「その差は驚くほど急速に縮まりつつある」と述べています。
「オープンソース モデルはより高速で、よりカスタマイズ可能で、比較的に高性能です。」
オープンソースの代替手段の台頭
しかし、 「比較的有能」とは何を意味するのでしょうか?投資とパラメーター (言語モデルの複雑さの測定単位) の数で測定されるその能力。つまり、あなた自身の例によれば、オープンソース プロジェクトは次のようになります。
「彼らは、我々が1,000万ドルと5,400億のパラメータを必要としたのを、100ドルと130億のパラメータで達成しています。」
そしてここに、この記事の著者の懸念に対する鍵がある。 「そして、彼らは(これらすべてを)数カ月ではなく、数週間でやっているのだ」。次に、レポートでは、2023 年 3 月にコミュニティがMeta の LLaMA モデルにアクセスできるようになって以来の急速な進化について取り上げています。
「[LLaMA] には指示も、会話の調整も、RLHF もありませんでした。しかし、コミュニティは、与えられた内容の意味をすぐに理解しました。そして、わずか 1 か月後に私たちはここにいます。すでに指示を調整した亜種が存在します。量子化、品質向上、人間による評価、マルチモダリティ、RLHF など。」
そして、このドキュメントの発行時点では、 LLaMA 2 とLLaMA 3 、あるいはMistral モデル はまだリリースされておらず、それらはすべて、オープンソース AI モデルの急速な進歩を示す完璧な例であることを思い出してください。
文書には、「最も重要なことは、LLM のトレーニングと実験の参入障壁をほぼ最小限に抑え、規模の問題を解決したということです」と記載されています。 「人間は、比較的強力なコンピュータを装備し、一晩で、最近まで OpenAI や Google のような大規模な組織にしか手の届かないものを達成しました。」
実際、このアイデアを図で説明するために、文書には Vicuna オープンソース モデル Web サイトから抽出したグラフが含まれており、LLaMA へのパブリック アクセスとそれに基づく 2 つの無料モデルの開始までの経過時間を含むように修正されています。合計 3 週間:
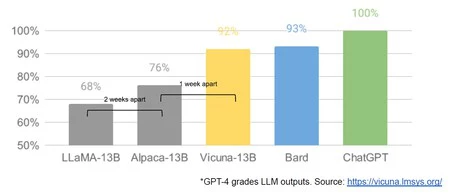
次に、匿名の著者は、オープンソース LLM の台頭と、同様にオープンソースの画像生成モデルの台頭とを比較します。
「多くの意味で、これは誰にとっても驚くべきことではありません。オープンソース LLM の現在のブームは、イメージング分野での経験に続いて起こっています。[…]多くの人がそれを言語モデルの「安定普及の瞬間」と呼んでいます。 。」
オープンソースに対抗することはできない
しかし、こうしたことは Google にどのような影響を与えるのでしょうか?同報告書は、今後Googleがこの分野で競争するのはさらに困難になるだろうと予測しており、「利用制限のない無料で高品質な代替品があれば、誰が利用制限のあるGoogle製品にお金を払うだろうか?」としている。
いずれにせよ、唯一の問題は、競合モデルの制限がないことだけではなく、 Google の秘密かつ独自の開発モデル自体にもあります。
「私たちのテクノロジーの秘密を守ることは、失敗する運命にあるギャンブルでした。Google の研究者は常に他の企業に行っているので、[これらの企業] は私たちが知っているすべてを知っていると考えることができます。そして、そのパイプラインがオープンである限り、それは続くでしょう。」 。
その一方で、世界中の研究機関は、フリー ソフトウェアのおかげで、他の研究機関が開発したものをさらに発展させるために協力し続けています。 「外部のイノベーションによって秘密の価値が薄れていく一方で、私たちは秘密をしっかりと守り続けることもできるし、お互いから学ぼうとすることもできる。」
同氏はまた、個人の開発者が企業自身よりもイノベーションにおいて機敏になる 2 つの要因を挙げました。
- まず、LLM への自由なアクセスを「個人使用」に制限するライセンスによって制限されていません(LLaMA の場合)。
- 第 2 に、特定の用途向けにカスタマイズされた LLM の多様性は、開発者がこれらのユースケース (安定した拡散に基づいたアニメ画像ジェネレーターなど) に熱心に取り組んでいることによるものです。
「それらは、特定のサブジャンルに深く没頭している人々によって使用され、作成されており、私たちが匹敵することを期待できないほどの深い知識と共感をもたらします。」
メタは新しい Google です
文書によると、「逆説的だが、このすべてにおいて明確な勝者はメタだけだ。漏洩したモデルは彼らのものだったので、彼らは地球全体の無料労働力を手に入れたことになる[…]彼らが行ったイノベーションを自社の製品に直接組み込むことを妨げるものは何もない」 。」
「エコシステムを所有することの価値は、どれだけ誇張してもしすぎることはありません。Google自体も、Chrome や Android などのオープンソース製品でこのパラダイムをうまく利用してきました。」
OpenAIについてはどうですか?
「私たちがモデルをコントロールすればするほど、オープンな代替手段はより魅力的なものになります。GoogleもOpenAIも、自社のモデルがどのように使用されるかを厳密にコントロールできるモデルを公開することに防衛的に傾いています。しかし、このコントロールはフィクションです。」
報告書の著者は、「 OpenAIは問題ではない。彼らはオープンソースに関するスタンスにおいて、私たちと同じ間違いを犯している」と率直に語った。彼はまた、OpenAI がその名に恥じず、「オープン」に戻らない限り、最終的にその地位を失うことになるだろうと予測しました。 「この意味で、少なくとも(Googleでは)最初の一歩を踏み出すことができます。」